Fixed images settings and typo
Showing
- docs/_posts/2020-03-27-brevitas-quartznet-release.md 12 additions, 8 deletionsdocs/_posts/2020-03-27-brevitas-quartznet-release.md
- docs/img/JasperVertical4.jpg 0 additions, 0 deletionsdocs/img/JasperVertical4.jpg
- docs/img/JasperVertical4.png 0 additions, 0 deletionsdocs/img/JasperVertical4.png
- docs/img/QuartzNet.jpg 0 additions, 0 deletionsdocs/img/QuartzNet.jpg
- docs/img/QuartzNet.png 0 additions, 0 deletionsdocs/img/QuartzNet.png
- docs/img/WERMB.jpg 0 additions, 0 deletionsdocs/img/WERMB.jpg
- docs/img/WERMB.png 0 additions, 0 deletionsdocs/img/WERMB.png
- docs/img/WERNops.jpg 0 additions, 0 deletionsdocs/img/WERNops.jpg
- docs/img/WERNops.png 0 additions, 0 deletionsdocs/img/WERNops.png
- docs/img/quartzPic1.jpg 0 additions, 0 deletionsdocs/img/quartzPic1.jpg
- docs/img/quartzPic1.png 0 additions, 0 deletionsdocs/img/quartzPic1.png
docs/img/JasperVertical4.jpg
0 → 100644
{kind=link}

33.3 KiB
docs/img/JasperVertical4.png
deleted
100644 → 0
{kind=link}

25.2 KiB
docs/img/QuartzNet.jpg
0 → 100644
{kind=link}
108 KiB
docs/img/QuartzNet.png
deleted
100644 → 0
{kind=link}
167 KiB
docs/img/WERMB.jpg
0 → 100644
{kind=link}
68.9 KiB
docs/img/WERMB.png
deleted
100644 → 0
{kind=link}
26.1 KiB
docs/img/WERNops.jpg
0 → 100644
{kind=link}
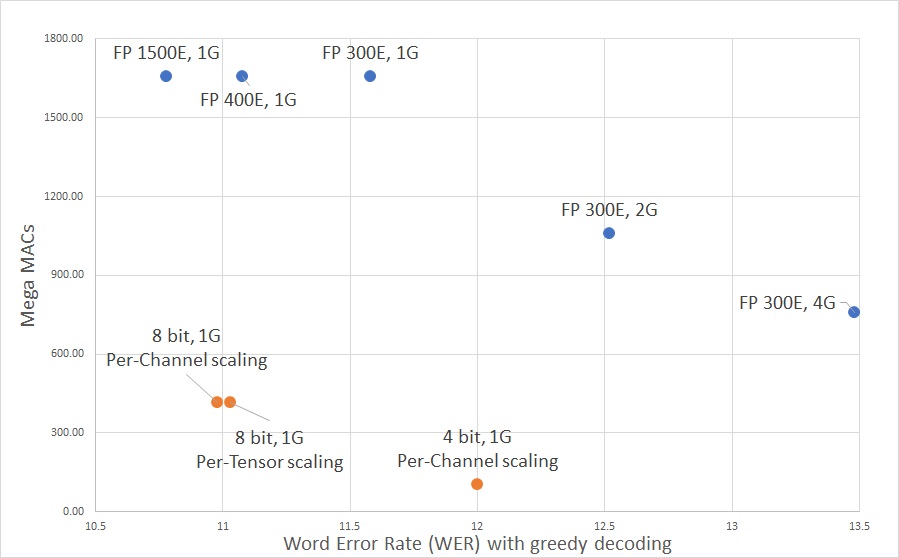
67.6 KiB
docs/img/WERNops.png
deleted
100644 → 0
{kind=link}
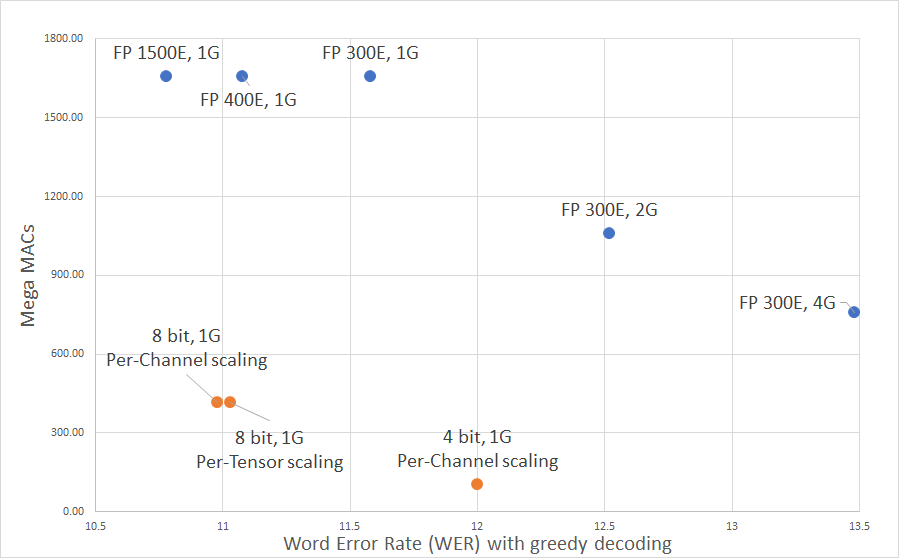
23.1 KiB
docs/img/quartzPic1.jpg
0 → 100644
{kind=link}
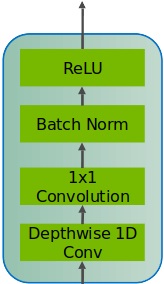
23.1 KiB
docs/img/quartzPic1.png
deleted
100644 → 0
{kind=link}
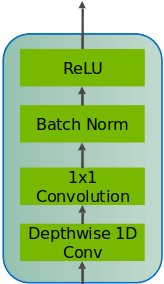
11.1 KiB